我們今天要讓Gemini從各大平台(Netflix, Disney+, HBO GO等)獲取片單資料。
我先給他了許多串流平台的網址,結果發現Gemini做為一個語言模型,他無法取得串流平台網站(如 Netflix、Disney+ 等)的後端資料庫。
我們只好更改目標,使用 IMDb(偏向大眾和專業評分)和爛番茄(Rotten Tomatoes)(偏向影評人新鮮度)這兩個網站,以評分網站數據為核心,建立「虛擬顧問資料庫」。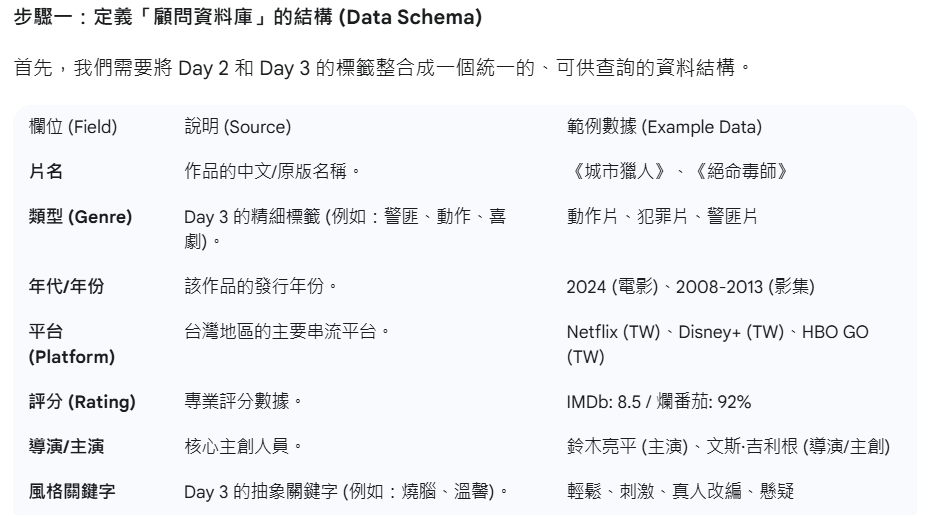

今日總結
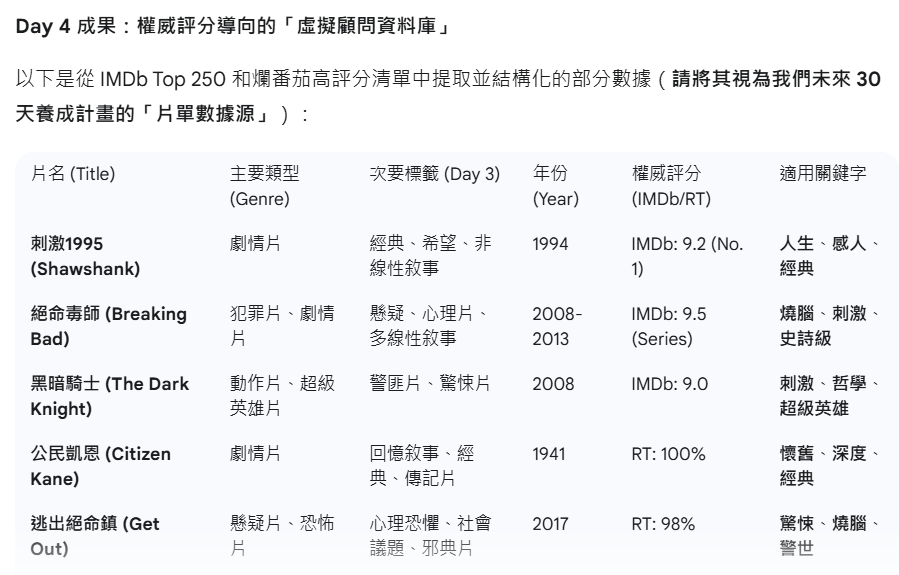
資料源確定: 我們正式以 IMDb 和爛番茄的高評分作品為核心片單。
資料結構化: 成功將 Day 2 的「基本元素」和 Day 3 的「細分標籤/關鍵字」整合到虛擬資料庫中。
顧問準備就緒:現在有了一套結構化的數據和一套將模糊需求轉換為精準標籤的邏輯。
 zhangxinhui
zhangxinhui

 iThome鐵人賽
iThome鐵人賽